Join the discussion in the GitHub community to tell us what you think.
Why this matters right now
Software supply chain attacks aren’t slowing down. Over the past year, incidents targeting projects like tj-actions/changed-files, Nx, and trivy-action show a clear pattern: attackers are targeting CI/CD automation itself, not just the software it builds.
The playbook is consistent:
- Vulnerabilities allow untrusted code execution
- Malicious workflows run without observability or control
- Compromised dependencies spread across thousands of repositories
- Over-permissioned credentials get exfiltrated via unrestricted network access
Today, too many of these vulnerabilities are easy to introduce and hard to detect. We’re working to address this gap.
What we’re building
Our 2026 roadmap focuses on securing GitHub Actions across three layers:
- Ecosystem: deterministic dependencies and more secure publishing
- Attack surface: policies, secure defaults, and scoped credentials
- Infrastructure: real-time observability and enforceable network boundaries for CI/CD runners
This isn’t a rearchitecture of Actions; it’s a shift toward making secure behavior the default, helping every team to become CI/CD security experts.
Here’s what’s coming next, and when.
1. Building a more secure Actions ecosystem
The current challenge
Action dependencies are not deterministic and are resolved at runtime. Workflows can reference a dependency by various mutable references including tags and branches.
That means what runs in CI isn’t always fixed or auditable. Maintainers of Action workflows, for instance, typically manage updates through mutable tags that point to the latest commits of a major or minor release.
Using immutable commit SHAs helps, but it’s hard to manage at scale and transitive dependencies remain opaque.
That mutability has real consequences. When a dependency is compromised, the change can propagate immediately across every workflow that references it.
As recent supply chain incidents have shown, we can’t rely on the security posture of every maintainer and repository in the ecosystem to prevent the introduction of malicious code.
What’s changing: workflow-level dependency locking
We’re introducing a dependencies: section in workflow YAML that locks all direct and transitive dependencies with the commits SHA,
Think of it as Go’s go.mod + go.sum, but for your workflow with complete reproducibility and auditability.
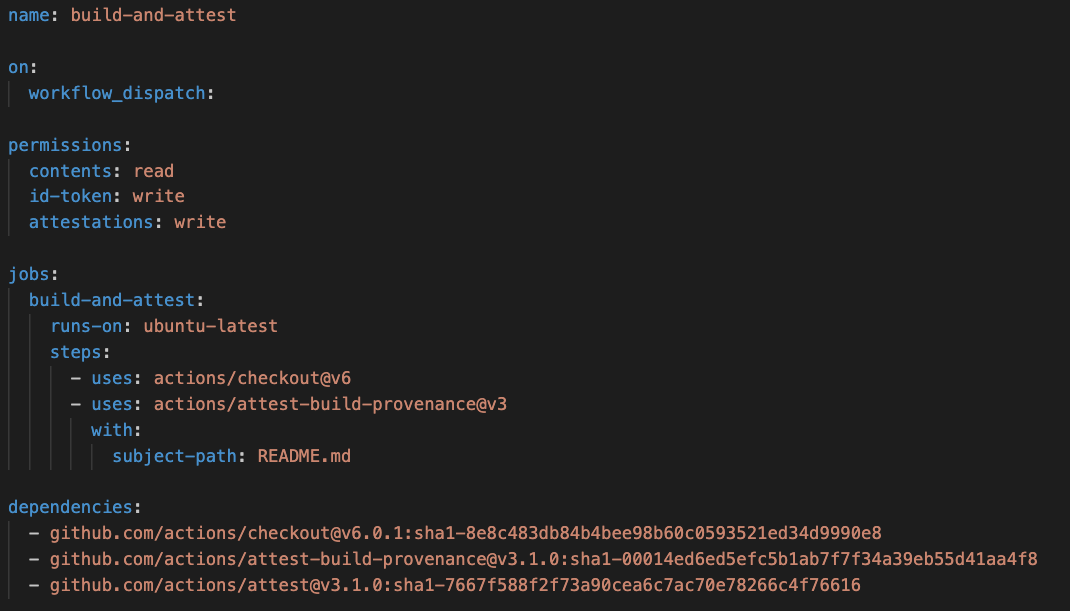
What this changes in practice:
- Deterministic runs: Every workflow executes exactly what was reviewed.
- Reviewable updates: Dependency changes show up as diffs in pull requests.
- Fail-fast verification. Hash mismatches stop execution before jobs run.
- Full visibility. Composite actions no longer hide nested dependencies.
In your workflows, this means you will be able to:
- Resolve dependencies via GitHub CLI
- Commit the generated lock data into your workflow
- Update by re-running resolution and reviewing diffs
Our current milestones for lock files are as follows:
Milestones:
| Phase | Target |
|---|---|
| Public preview | 3-6 months |
| General availability | 6 months |
Future: hardened publishing with immutable releases
Beyond consumption, we’ll harden how workflows are published into the Actions ecosystem. On the publishing side, we’re moving away from mutable references and towards immutable releases with stricter release requirements.
Our goal is to:
- Make it clearer on how and when code to enters the ecosystem
- Create a central enforcement point for detecting and blocking malicious code
2. Reducing attack surface with secure defaults
The current challenge
GitHub Actions is flexible by design. Workflows can run:
- In response to many events
- Triggered by various actors
- With varying permissions
But as organizations scale, the relationship between repository access and workflow execution needs more granularity. Different workflows, teams, and enterprises need very different levels of exposure. Moreover, it leads to over-permissioned workflows, unclear trust boundaries, and configurations that are easy to get wrong.
Attacks like Pwn Requests show how subtle differences in event triggers, permissions, and execution contexts can be abused to compromise sensitive environments. Scaling this across thousands of repositories and contributors requires centralized policy.
What’s changing: policy-driven execution
We’re introducing workflow execution protections built on GitHub’s ruleset framework.
Instead of reasoning about security across individual YAML files, you define central policies that control:
- Who can trigger workflows
- Which events are allowed
This shifts the model from distributed, per-workflow configuration that’s difficult to audit and easy to misconfigure, to centralized policy that makes broad protections and restrictions visible and enforceable in one place.
Our core policy dimensions include:
- Actor rules specify who can trigger workflows such as individual users, roles like repository admins, or trusted automation like GitHub Apps, GitHub Copilot, or Dependabot.
- Event rules define which GitHub Actions events are permitted like push, pull_request, workflow_dispatch, and others.
For example, an organization could restrict workflow_dispatch execution to maintainers, preventing contributors with write access from manually triggering sensitive deployment or release workflows. Separately, they could prohibit pull_request_target events entirely and only allow pull_request, ensuring workflows triggered by external contributions run without access to repository secrets or write permissions.
These protections scale across repositories without per-workflow configuration. Enterprises apply consistent policies organization-wide using rulesets and repository custom properties, reducing operational risk and governance overhead.
Why this matters for attack prevention:
Many CI/CD attacks depend on:
- Confusing event behavior
- Unclear permission boundaries
- Unexpected execution contexts
Execution protections reduce this attack surface by ensuring that workflows that don’t meet policy never run.
Safe rollout: evaluate mode
To help teams adopt these protections safely, workflow execution rules support evaluate mode. In evaluate mode, rules are not enforced, but every workflow run that would have been blocked is surfaced in policy insights (similar to repository rulesets). This lets organizations assess the impact of new policies before activating enforcement, identifying affected workflows, validating coverage, and building confidence without disrupting existing automation.
Milestones:
| Phase | Target |
|---|---|
| Public preview | 3-6 months |
| General availability | 6 months |
Scoped secrets and improved secret governance
The current challenge
Secrets in GitHub Actions are currently scoped at the repository or organization level. This makes secrets difficult to use safely, particularly with reusable workflows where credentials flow broadly by default. Teams need finer-grained controls to bind credentials to specific execution contexts.
What’s changing: scoped secrets
Scoped secrets introduce fine-grained controls that bind credentials to explicit execution contexts. Secrets can be scoped to:
- Specific repositories or organizations
- Branches or environments
- Workflow identities or paths
- Trusted reusable workflows without requiring callers to pass secrets explicitly
What this changes
- Secrets are no longer implicitly inherited
- Access requires matching an explicit execution context
- Modified or unexpected workflows won’t receive credentials
Reusable workflow secret inheritance
Reusable workflows enable powerful composition, but implicit secret inheritance has caused friction within platform teams. When secrets automatically flow from a calling workflow into a reusable workflow, trust boundaries blur, and credentials can be exposed to execution paths that were never explicitly approved.
With scoped secrets:
- Secrets are bound directly to trusted workflows
- Callers don’t automatically pass credentials
- Trust boundaries are explicit
Permission model changes for Action Secrets
We’re separating code contributions from credential management.
That means write access to a repository will no longer grant secret management permissions and helps us move toward least privilege by default.
This capability will instead be available through a dedicated custom role and will remain part of the repository admin, organization admin, and enterprise admin roles.
Together, these changes make it possible to ensure credentials are only issued when both the workflow and the execution context are explicitly trusted.
Milestones:
| Capability | Phase | Target |
|---|---|---|
| Scoped secrets & reusable workflow inheritance | Public preview | 3-6 months |
| Scoped secrets & reusable workflow inheritance | GA | 6 months |
| Secrets permission | GA | 3-6 months |
Our future goal: building a unified policy-first security model
Longer term, our goal is fewer implicit behaviors, fewer per-workflow configurations, and more centralized, enforceable policy.
We want to give enterprises the ability to define clear trust boundaries for workflow execution, secret access, and event triggers without encoding complex security logic into every workflow file.
This includes expanding policy coverage, introducing richer approval and attestation gates, and consolidating today’s fragmented controls into a single governance surface.
3. Endpoint monitoring and control for CI/CD infrastructure
The current challenge
CI/CD infrastructure is critical infrastructure. GitHub Actions runners execute untrusted code, handle sensitive credentials, and interact with external systems and input.
But historically:
- Visibility is limited
- Controls are minimal
- Investigation is reactive
When something goes wrong, organizations often have limited insight into what executed, where data flowed, or how a compromise unfolded.
Recent attacks have shown how unrestricted execution environments amplify impact, enabling secret exfiltration, unauthorized publishing, and long dwell times. Securing CI/CD requires treating its workloads as a first-class security domain with explicit controls and continuous visibility.
What’s changing
We’re introducing enterprise-grade endpoint protections for GitHub Actions, starting with the Actions Data Stream (visibility) and the native egress firewall (control).
Increased visibility with Actions Data Stream
CI/CD visibility today is fragmented with limited insight or monitoring. As automation becomes more powerful, and more targeted, organizations need the ability to observe execution behavior continuously, not just investigate after an incident.
The Actions Data Stream provides:
- Near real-time execution telemetry
- Centralized delivery to your existing systems
Supported destinations:
- Amazon S3
- Azure Event Hub / Data Explorer
Events are delivered in batches with at least once delivery guarantees, using a common schema that allows reliable indexing and correlation in your chosen platform.
What you can observe:
- Workflow and job execution details across repositories and organizations.
- Dependency resolution and action usage patterns
- (Future) Network activity and policy enforcement outcomes
Why this matters
Without centralized telemetry, anomalies go unnoticed, detection happens after an incident, and responses are delayed.
The Actions Data Stream solves this problem by making CI/CD observable like any other production system.
Milestones:
| Phase | Target |
|---|---|
| Public preview | 3-6 months |
| General availability | 6-9 months |
Native egress firewall for GitHub-hosted runners
The current challenge
GitHub-hosted runners currently allow unrestricted outbound network access. That means:
- Easy data exfiltration
- No restrictions on what package registries can be used to obtain dependencies
- Unclear distinctions between expected and unexpected network traffic
What’s changing
We’re building a native egress firewall for GitHub-hosted runners, treating CI/CD infrastructure as critical infrastructure with enforceable network boundaries.
The firewall operates outside the runner VM at Layer 7. It remains immutable even if an attacker gains root access inside the runner environment. Organizations define precise egress policies, including:
- Allowed domains and IP ranges
- Permitted HTTP methods
- TLS and protocol requirements
The firewall provides two complementary capabilities:
- Monitor: Organizations can monitor all outbound network traffic from their runners, with every request automatically audited and correlated to the workflow run, job, step, and initiating command. This visibility gives teams the data they need to understand what their workflows connect to, build informed allowlists, and assess the impact of restrictions before enforcing them.
- Enforce: Organizations can enforce egress policies that block any traffic not explicitly permitted, ensuring that only approved destinations are reachable from the build environment.
Together, monitoring and enforcement create a safe adoption path: observe traffic patterns first, develop precise allowlists based on real data, then activate enforcement with confidence.
Milestones:
| Phase | Target |
|---|---|
| Public preview | 6-9 months |
Our future goal: treating runners as protected endpoints
Runners shouldn’t be treated as disposable black boxes. We’re expanding toward:
- Process-level visibility
- File system monitoring
- Richer execution signals
- Near real-time enforcement
What this means in practice
CI/CD has become part of the critical infrastructure for enterprises and open source. The failures we’ve seen around dependency management, complex and implicit trust boundaries, secret handling, and observability have led to an increase in attacks across the software supply chain.
The 2026 GitHub Actions roadmap responds directly. We’re shifting the platform toward secure-by-default, verifiable automation with a focus on disrupting these attacks.
That means:
- Workflows become deterministic and reviewable
- Secrets are explicitly scoped and not broadly inherited
- Execution is governed by policy, not YAML alone
- Runners become observable and controllable systems
GitHub Actions remains flexible. Our roadmap is designed to move Actions toward a secure by default, auditable automation platform without requiring every team to rebuild their CI/CD model from scratch.
The post What’s coming to our GitHub Actions 2026 security roadmap appeared first on The GitHub Blog.